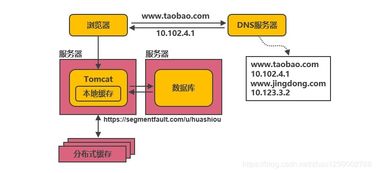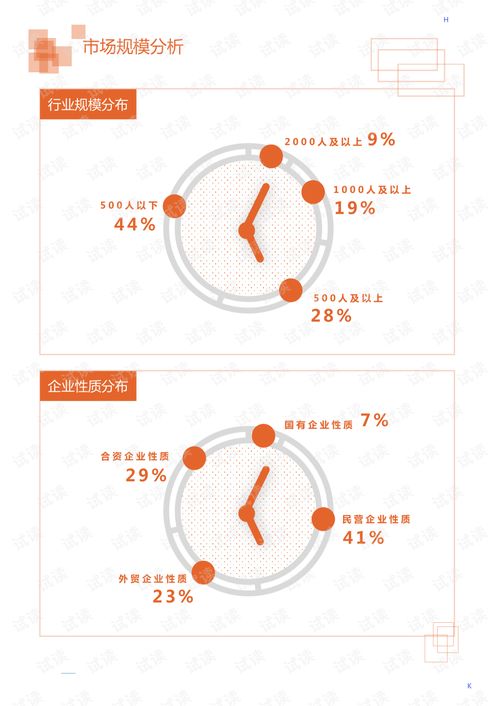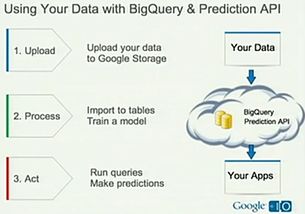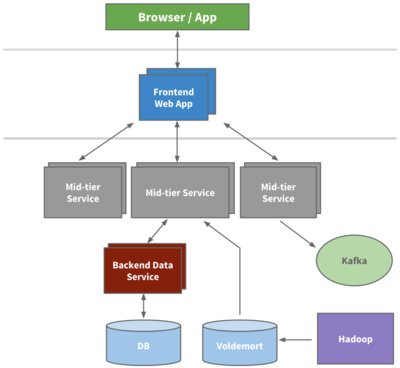
在过去的十年中,LinkedIn 的架构经历了从单体到微服务、从集中式到分布式的重大演进,尤其是在数据处理服务方面,其发展轨迹堪称行业典范。数据处理作为 LinkedIn 业务的核心支撑,不仅驱动了用户推荐、内容分发和实时分析等功能,还应对了爆炸式增长的数据规模和复杂性。本文将回顾 LinkedIn 在过去十年中数据处理服务的演变,从早期的基础设施到如今的智能平台,探讨其背后的技术决策、关键里程碑以及未来趋势。
早期阶段(约 2010-2015 年):单体架构与批处理为主
在 LinkedIn 的早期,架构以单体设计为主,数据处理主要依赖批处理系统,如 Hadoop 生态系统。这一时期,数据量虽快速增长但相对可控,LinkedIn 开始构建数据湖,使用 Apache Kafka 作为消息队列来支持数据流的传输。数据处理服务侧重于离线分析,例如用户行为日志处理和批量推荐算法,但实时性需求不高。挑战包括数据一致性和扩展性问题,LinkedIn 通过引入分区和复制策略来优化。
中期演进(约 2015-2020 年):微服务化与实时处理兴起
随着 LinkedIn 用户量突破 5 亿,数据处理需求转向实时化和高可用性。公司大力推动微服务架构转型,数据服务被拆分为独立的组件,如 LinkedIn 的 Espresso 分布式数据库和 Samza 流处理框架。这一阶段,数据处理服务开始强调低延迟,支持实时推荐、通知系统和欺诈检测。例如,Samza 与 Kafka 集成,实现了事件驱动的数据处理管道,显著提升了用户体验。同时,数据治理和隐私保护成为焦点,LinkedIn 建立了更严格的数据访问控制机制。
近期发展(约 2020 年至今):云原生与 AI 驱动的智能平台
进入 2020 年代,LinkedIn 全面拥抱云原生技术,数据处理服务转向容器化和无服务器架构。利用 Kubernetes 和云基础设施,服务实现了更高的弹性和成本效率。AI 和机器学习深度集成,数据处理不再局限于存储和分析,而是驱动个性化内容、职业洞察和自动化决策。例如,LinkedIn 使用机器学习模型进行实时内容排序,并通过数据湖和 Delta Lake 技术确保数据质量。数据流水线更加自动化,支持多租户和跨地域部署,以应对全球化业务的复杂性。
关键挑战与经验教训
十年来,LinkedIn 在数据处理服务上面临的主要挑战包括数据规模爆炸、实时性需求和安全性问题。通过采用开源工具(如 Kafka、Samza 和 Pinot)和内部创新,LinkedIn 实现了从批处理到流处理的平滑过渡。经验表明,模块化设计、持续监控和敏捷迭代是成功的关键。例如,在 2016 年的一次大规模数据迁移中,LinkedIn 通过分阶段部署避免了服务中断。
未来展望
LinkedIn 的数据处理服务预计将进一步智能化,结合边缘计算和联邦学习,以提升隐私保护和响应速度。同时,随着 AI 伦理和法规的演进,数据服务将更注重透明度和合规性。LinkedIn 的架构演进不仅展示了技术的前沿趋势,也为其他企业提供了宝贵参考。
LinkedIn 的十年数据处理服务之旅是一个从传统批处理到实时智能化的转型故事。通过持续的架构创新,LinkedIn 不仅支撑了其社交网络的增长,还推动了整个行业的数据处理标准。无论是早期的基础设施建设,还是如今的 AI 赋能,LinkedIn 始终以用户为中心,驱动数据价值最大化。