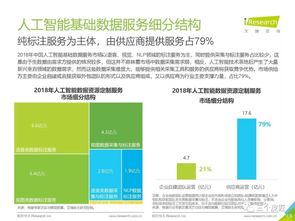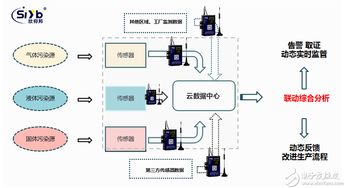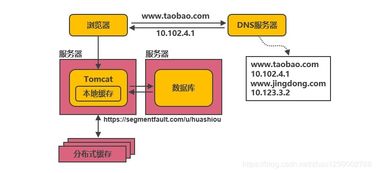
在数字化浪潮的推动下,分布式系统已成为支撑现代互联网服务、大数据分析与人工智能应用的核心架构。其演进历程,特别是数据处理服务的演进,深刻反映了技术与业务需求的双重驱动。本文将梳理这一演进流程,展现数据处理服务如何从简单走向复杂,从集中迈向智能。
第一阶段:单体集中式与数据孤岛
在早期,系统通常是单体架构。数据处理服务内嵌于单一应用中,直接读写单一数据库。数据存储、计算逻辑和业务表现层紧密耦合。这种模式的优点是简单、易于开发和部署。随着数据量和业务复杂度的增长,其弊端凸显:性能瓶颈难以突破,任何模块的修改都可能影响全局,系统扩展性极差。数据被禁锢在特定的应用内,形成“数据孤岛”,无法实现跨业务的整合与价值挖掘。
第二阶段:垂直拆分与数据库分离
为应对单体架构的挑战,系统演进的第一步是“垂直拆分”(或称为“烟囱式架构”)。根据业务功能将大系统拆分为多个独立的子系统,如用户服务、订单服务、商品服务等。每个子系统拥有自己独立的数据库,实现了技术栈和团队职责的分离。数据处理开始按业务域进行划分。此时的数据库仍是集中式的(如主从复制),跨服务的复杂查询和事务处理变得异常困难,数据一致性面临挑战。
第三阶段:服务化与分布式数据库兴起
随着微服务架构理念的普及,系统进入全面的“服务化”阶段。每个微服务都是独立部署、运行和演进的进程,通过轻量级协议(如HTTP/REST、gRPC)进行通信。这对数据处理服务提出了更高要求:
- 数据库按服务拆分:每个微服务拥有其私有的数据库,实现彻底的解耦。
- 分布式事务需求:跨多个服务的业务操作需要分布式事务解决方案,如Saga模式、TCC(Try-Confirm-Cancel)或基于消息队列的最终一致性。
- 分布式数据库登场:为满足海量数据存储、高并发访问和高可用性,NewSQL(如TiDB、CockroachDB)和云原生分布式数据库(如AWS Aurora、Google Spanner)开始广泛应用,它们在提供横向扩展能力的尽可能保持了SQL和ACID事务特性。
此阶段,数据处理的核心矛盾是“分散的数据存储”与“全局的数据视图/分析需求”之间的冲突。
第四阶段:数据中台与流批一体处理
为解决数据分散问题,并最大化数据价值,“数据中台”概念应运而生。它并非一个具体技术,而是一种组织架构和战略,旨在构建统一、可复用、标准化的数据能力平台。在技术层面,这催生了新一代数据处理服务模式:
- 中心化数据仓库与数据湖:通过ETL/ELT流程,将各业务系统的数据汇聚到统一的数据仓库(如Snowflake、BigQuery)或数据湖(如基于HDFS、S3的存储)中,形成企业级单一事实来源。
- 流批一体处理框架:传统Lambda架构(批处理和流处理两套系统)的运维复杂度高。以Apache Flink为代表的流批一体引擎,实现了用同一套API和运行时处理实时流数据和历史批量数据,极大地简化了架构。数据处理服务从“T+1”的离线报表,迈向实时监控、实时推荐和实时风控。
- 数据服务化:将清洗、整合后的数据,通过API的方式透明、安全地提供给前台业务应用,使数据消费像调用普通服务一样简单。
第五阶段:云原生、智能化与无服务器化
当前,分布式数据处理服务正全面拥抱云原生和智能化。
- 云原生数据服务:利用容器化(Docker)、编排(Kubernetes)、服务网格(Istio)和声明式API,实现数据处理服务的弹性伸缩、故障自愈和高效运维。存储计算分离架构成为主流,使得两者可以独立扩展。
- Serverless数据处理:用户无需关心服务器基础设施,只需关注业务逻辑和数据。云厂商提供的Serverless化服务,如AWS Glue(ETL)、Azure Functions(事件驱动计算)、Google BigQuery(数仓),实现了极致的弹性与成本优化,按使用量付费。
- AI驱动的智能数据管理:机器学习被深度融入数据处理全链路。包括:智能数据分级与治理、自动化的数据质量检测与修复、基于查询历史的自动性能优化(如自动索引、物化视图)、以及智能的元数据管理与数据发现工具。数据处理服务本身变得更加“聪明”和自动化。
演进的核心驱动力与未来展望
纵观演进流程,驱动力始终是规模(Scale)、复杂度(Complexity) 和速度(Speed)。从处理GB级数据到PB/EB级数据,从结构化数据到多模态数据,从离线分析到实时智能决策,每一次架构演进都是为了在新的挑战下重新找到简单、可靠与效率的平衡点。
随着边缘计算的普及和物联网数据的爆发,分布式数据处理将进一步向“云-边-端”协同演进。数据隐私与安全(如联邦学习、差分隐私)、绿色计算(降低数据处理能耗)也将成为演进的重要维度。数据处理服务将更深地隐藏于底层,作为智能时代无处不在的水和电,为上层应用提供源源不断的数据动能。