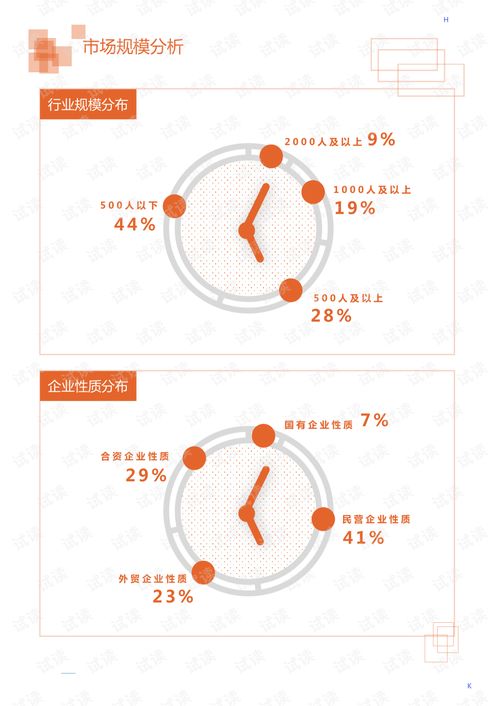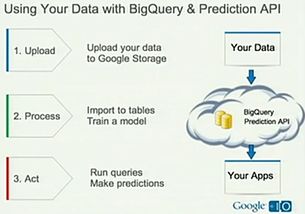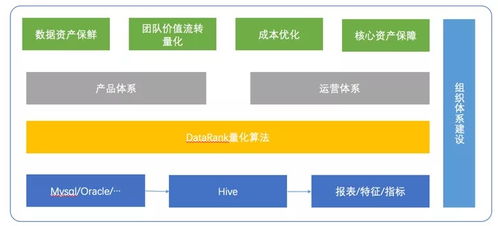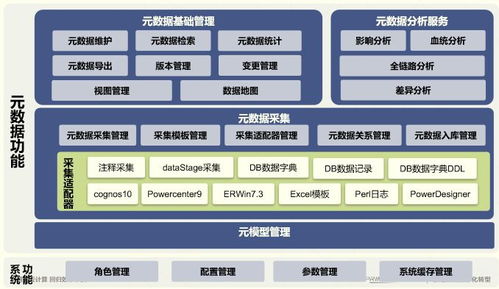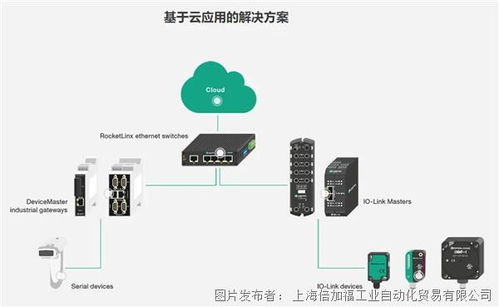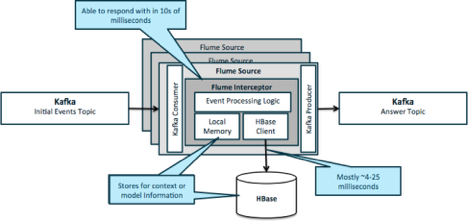
在当今大数据时代,企业对于数据处理的需求日益增长,不仅需要处理海量历史数据,还需具备准实时数据处理能力。Apache Hadoop作为分布式系统的基础框架,通过合理架构设计可实现准实时数据处理,以下介绍几种典型的架构模式。
Lambda架构是最经典的准实时数据处理模式。该架构包含批处理层、速度层和服务层三层结构。批处理层使用Hadoop MapReduce或Spark处理全量数据,保证数据准确性;速度层通过Storm或Spark Streaming处理实时数据流,提供低延迟响应;服务层则合并两层结果对外提供查询服务。这种架构兼顾了数据准确性和处理时效性,但需要维护两套代码逻辑。
Kappa架构是Lambda架构的简化版本。该架构取消了批处理层,完全基于流式处理。通过将历史数据重新注入流处理系统,使用同一套代码逻辑处理历史和实时数据。Kafka通常作为消息队列,配合Spark Streaming或Flink实现数据流动。这种架构简化了系统复杂度,但要求流处理系统具备精确一次语义和状态管理能力。
基于Hadoop生态的混合架构也值得关注。例如使用HDFS存储历史数据,HBase提供实时查询,Kafka作为数据管道,Spark进行流批一体处理。这种架构充分利用Hadoop生态组件,通过合理组合实现准实时数据处理需求。
在实际应用中,架构选择需考虑业务场景、数据规模、时效要求等因素。无论采用何种架构,都需要关注数据一致性、系统可扩展性和运维复杂度等问题。随着技术的发展,基于Hadoop的准实时数据处理架构将持续演进,为企业数据驱动决策提供更强有力的支撑。